When the model is wrong: designing AI for the failure you know is coming
Bottom line: A probabilistic system will be wrong in production — not occasionally, not as a bug to be eliminated, but as a certainty to be designed for. Most teams design only the happy path and treat failure as an exception to handle later. Mature teams design the failure response as a first-class feature, climbing a ladder from prevention through detection, containment, recovery, and learning. Detection — knowing it failed — is only the middle rung, and teams that stop there have built a system that lets them watch failures they cannot contain or recover from. The measure of an AI system is not how rarely it fails. It is how well.
Your AI will be wrong. You are designing as if it won't.
There is a quiet assumption underneath most AI products: that the goal is a system that does not make mistakes, and that mistakes, when they happen, are defects to be fixed until they stop. This assumption is reasonable for traditional software, where a correctly written function is correct every time, and a bug is a fixable deviation from correctness. It is wrong for AI. A system built on a probabilistic model does not have a "correct" state it deviates from; being wrong some fraction of the time is not a bug in the system but a property of it. You can lower the error rate, but you cannot drive it to zero, and a design that assumes you can is a design that will be surprised by something it should have expected.
This matters because the assumption shapes where the engineering effort goes. If failure is an exception, you build the happy path thoroughly and treat error handling as an afterthought — a catch block, a generic apology, a fallback nobody designed with care. Then the system fails in production, as it always would, and the failure is handled badly because it was never really designed at all. The teams whose AI products feel trustworthy are not the ones whose models are mysteriously never wrong. They are the ones who accepted that the model would be wrong and designed what happens next as carefully as they designed what happens when it is right.
A probabilistic system being wrong is not a bug in the system. It is a property of it — and designing as if it weren't is the actual mistake.
Failure is a feature, not an exception
The reframe that separates reliable AI products from fragile ones is to treat the failure response as a feature with the same status as any other — designed, built, tested, and owned, rather than bolted on as exception handling. This is not pessimism; it is the same discipline that underlies all reliable engineering. Aircraft are designed around the assumption that components will fail. Distributed systems are designed around the assumption that machines and networks will fail. The reliability of those systems comes not from components that never fail but from designs that fail safely, contain the damage, and recover. AI deserves the same treatment, and for the same reason: the failure is not avoidable, so the only question is whether it is designed for.
Treating failure as a feature changes what "done" means. A feature is not done when it works on the happy path; it is done when it also fails well — when a wrong answer is caught, kept from causing harm, and replaced with something safe, and when the failure teaches the system to be less wrong next time. That is a higher bar than "it usually works," and it is the bar that production AI has to clear, because production is exactly where the failures the demo never showed will happen.
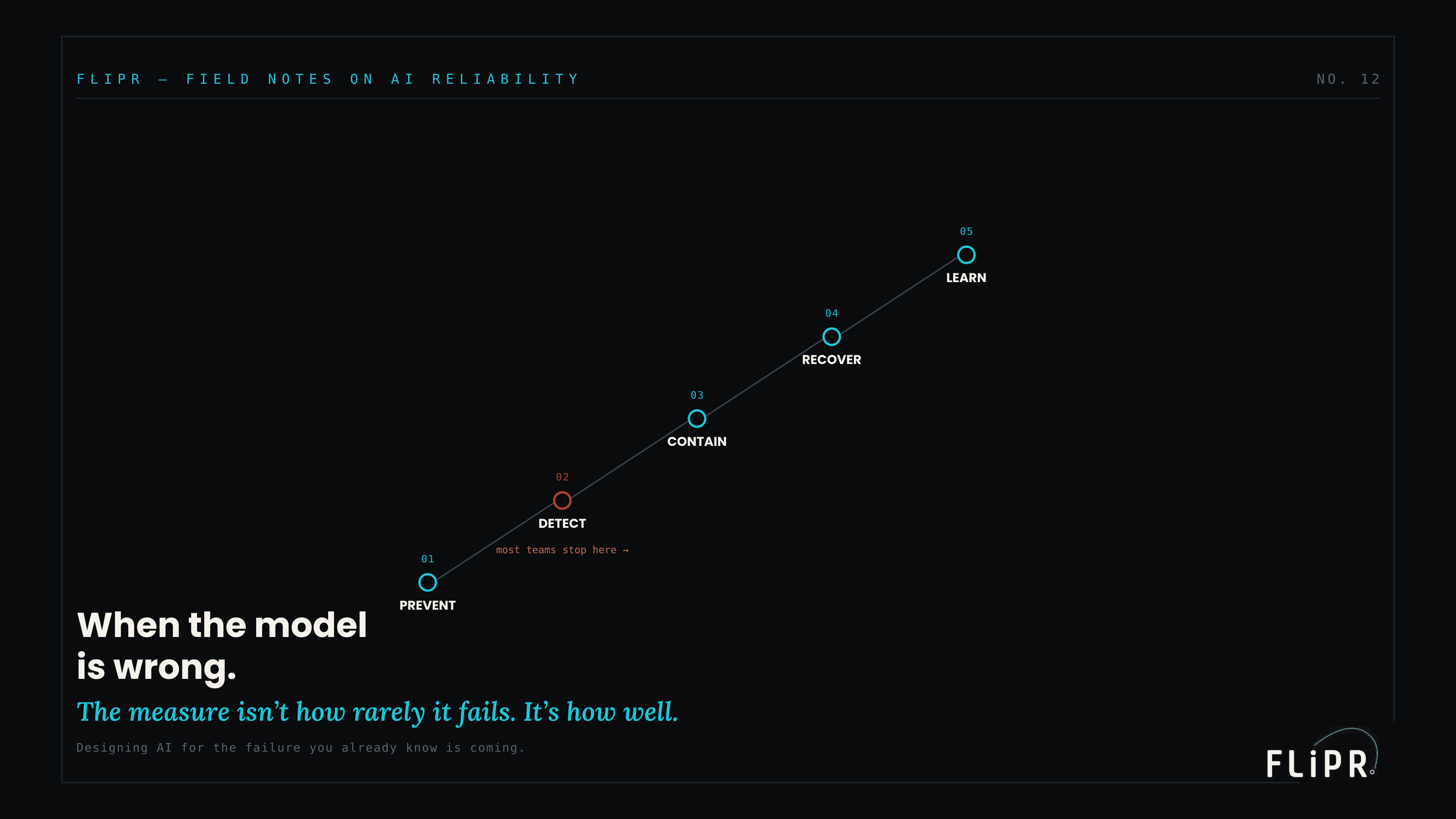
The Failure Ladder
The failure response is not one thing; it is five, arranged as a ladder you climb.
 Exhibit 1. Five responses to a wrong answer, in order. Detection is only the middle rung — and where most teams stop.
Exhibit 1. Five responses to a wrong answer, in order. Detection is only the middle rung — and where most teams stop.
The first rung is prevent: reduce how often the system is wrong in the first place, through better models, better retrieval, better prompts. The second is detect: know when it is wrong, through evaluation, monitoring, and confidence signals. The third is contain: limit how much damage a single wrong answer can do, by boxing in its blast radius. The fourth is recover: fail to a safe, graceful fallback that still serves the user. And the fifth is learn: feed the failure back so the same one does not happen again. The rungs are ordered, and the order matters: each rung addresses a failure the rung below it could not prevent. Most importantly, detection is only the second rung — it is necessary, but a system that detects failures it cannot contain or recover from has only bought itself a clear view of the damage. Knowing that the model is wrong, with no ability to stop the consequences, is a better seat from which to watch the failure, not a way to prevent it.
This is the trap many teams fall into. They invest heavily in evaluation and monitoring — the detection rung — and stop there, believing that knowing about failures is the same as handling them. It is not. The rungs above detect, containment and recovery, are where a detected failure is actually prevented from harming anyone, and a system that stops at detection has built sophisticated instrumentation for observing its own unhandled errors.
Detecting a failure you cannot contain or recover from does not prevent it. It just means you get to watch it happen in high resolution.
What each rung does — and why detect isn't enough
Each rung does a specific job, and stopping at any rung below the top leaves a specific cost unpaid.
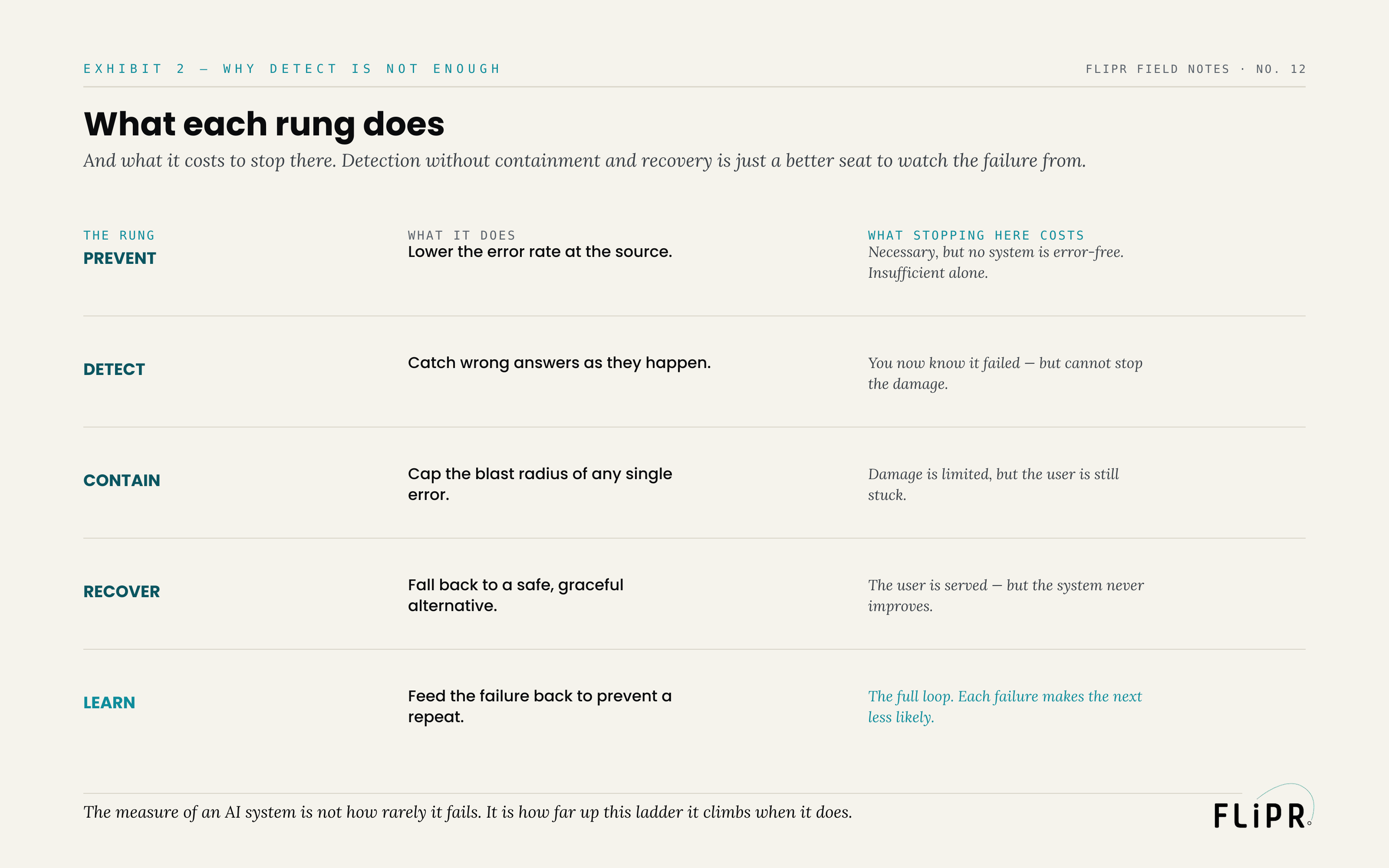 Exhibit 2. Detection without containment and recovery is just a better seat to watch the failure from.
Exhibit 2. Detection without containment and recovery is just a better seat to watch the failure from.
Prevent lowers the error rate at the source — necessary, but since no system is error-free, insufficient on its own. Detect catches wrong answers as they happen — but stopping here means you know it failed and still cannot stop the damage. Contain caps the blast radius so a single error cannot cascade — but stopping here means the damage is limited while the user is still stuck with a broken experience. Recover falls back to a safe alternative that still serves the user — but stopping here means the user is served while the system never learns, so the same failure recurs forever. And learn feeds the failure back into prevention, closing the loop so that each failure makes the next one less likely. Only at the top rung is the failure fully handled: caught, contained, recovered from, and turned into an improvement. Every rung below the top is a partial response, valuable but incomplete, and the cost of stopping early is paid in exactly the gap that rung was meant to close.
The practical lesson is that a reliable AI system needs the whole ladder, not a tall pile of one rung. A team with world-class detection and no containment is worse off than it thinks, because all that detection does is document failures it is powerless to stop.
What this looks like on Monday
Set two systems side by side, with the same underlying error rate. (This is an illustration, not an account of any specific engagement.)
 Exhibit 3. Both fail equally often; users trust only one. Illustrative, not a client account.
Exhibit 3. Both fail equally often; users trust only one. Illustrative, not a client account.
The first is designed for success. The happy path is built thoroughly, and failure is treated as an exception. When the model is wrong, a confident wrong answer reaches the user intact, because nothing was designed to catch it. One bad output can affect everything downstream, because there is no containment. Over time the same failures recur, because nothing feeds them back, and trust erodes with each one — users learn that the system is occasionally, unpredictably wrong and that being wrong has no guardrails.
The second is designed for failure. The failure path is a first-class feature. When the model is wrong, the error is caught, contained, and replaced with a safe fallback before it reaches the user as truth. Each error is boxed in before it can spread. And failures feed back, so the system and the trust in it both grow over time — users learn that even when the system is wrong, being wrong is handled gracefully and rarely twice the same way.
Same error rate. Both systems are wrong equally often, and they earn completely different levels of trust — because the difference was never how often they failed. It was how well.
Where this argument fails, and what it costs
There are limits to this, and they matter.
Failure design can be over-engineered, and a low-stakes system does not need the full ladder. If a wrong answer costs almost nothing and is trivially reversible, building elaborate containment and recovery for it is wasted effort — the depth of failure design should scale with the cost of failure, exactly as it does in the automation decision. There is also a category of failure that should hard-stop rather than degrade gracefully: in some high-stakes contexts, the right response to an uncertain or likely-wrong answer is to refuse and escalate to a human, not to serve a confident fallback, because a graceful-looking wrong answer can be more dangerous than an honest refusal. Graceful degradation is not always the goal; sometimes the goal is to stop. And resilience has a real cost — every rung of the ladder is engineering work, and a system that is genuinely low-stakes may rationally invest only in prevention and detection. The discipline is to climb as far up the ladder as the stakes justify, not to treat all five rungs as mandatory everywhere.
That bounds the claim. Scale the ladder to the cost of being wrong, prefer an honest hard-stop to a dangerous graceful fallback where the stakes demand it, and invest in resilience in proportion to what failure actually costs. The point is not maximal failure-handling everywhere; it is deliberate failure design wherever failure has real consequences.
The decision
Here is the move this points to as you design your next AI system, and it is concrete.
Before you ship, map your system against the ladder and find the rung you stopped at — and if the honest answer is "detection," recognize that you have built a way to watch failures rather than handle them. Design the failure path as a first-class feature: decide how a wrong answer is contained so it cannot cascade, what safe fallback the user gets when the model fails, and how that failure feeds back so it does not recur. Calibrate how far up the ladder you climb to the cost of being wrong, and where the stakes are high enough, build an honest hard-stop rather than a confident fallback. Treat "how does this fail" as a design question you answer on purpose, not a question production answers for you.
Your AI will be wrong in production — that is settled, not in doubt. What is still open is whether being wrong is something you designed for or something that happens to you. Climb the ladder as far as the stakes justify, design the failure path with the care you gave the happy path, and remember that detection is only the middle. The measure of your AI system is not how rarely it fails. It is how well it fails when it does — which is the response side of the detection that the companion piece on evals is built to provide, and the reason a human in the loop, in the piece on what not to automate, is really a containment rung in disguise.
Sources
- Deloitte — State of Generative AI in the Enterprise (2024–2025). Reliability, accuracy, and risk management among the leading obstacles to deploying AI in production. https://www2.deloitte.com/
- McKinsey — The State of AI (annual survey). Inaccuracy and reliability among the most-cited risks enterprises work to mitigate in AI deployment. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Bottom-line summary (one line)
A probabilistic system will be wrong in production, so design the failure response as a first-class feature — climb the Failure Ladder from prevent through detect, contain, recover, and learn — because detection alone just gives you a clear view of damage you cannot stop.
Suggested LinkedIn hooks (link back to the blog)
- Your AI will be wrong in production. That's not a bug to eliminate — it's a property of a probabilistic system. And most teams are designing as if it won't happen. [link]
- Detecting a failure you can't contain or recover from doesn't prevent it. It just means you watch it happen in high resolution. Detection is only the middle rung. [link]
- Two AI systems can fail equally often and earn completely different trust. The difference is never how often they fail — it's how well. Here's the ladder. [link]