Knowing what not to automate: the highest-leverage skill in enterprise AI
Bottom line: The skill that separates good AI programs from dangerous ones is the negative one — knowing which decisions must stay human. It is decided not by what AI can do but by two things it cannot change: the cost of being wrong, and how much the decision depends on context the model cannot see. Map a decision against those two axes and the answer becomes clear: automate where both are low, keep a human in the loop where one is high, and keep the decision fully human where both are. Capability is not the question. Consequence is.
"Can AI do it" is the wrong question
The question that drives most automation decisions is "can the model do this?" — and as models get more capable, the answer is "yes" for an ever-wider range of tasks. So the scope of what gets automated expands to track the scope of what is technically possible, and each individual decision looks justified: the model can do it, so why keep a person in the way? This is how organizations sleepwalk into automating things they should not, one reasonable-looking step at a time.
The flaw is that capability and advisability are different questions, and only one of them is about the model. "Can it" is a fact about the system's competence. "Should it" is a judgment about consequence — about what happens when the system is wrong, and about whether the decision turns on things the model cannot see. A model can be entirely capable of producing an answer and still be the wrong thing to put in charge of the decision, because automating a choice does not eliminate the risk in it; it relocates that risk to the worst possible place — a moment with no human present to catch the error the model was always eventually going to make. The right question is never whether AI can make a decision. It is whether it should, given what is at stake and what it cannot see.
Automating a decision does not remove its risk. It just moves the risk to the one moment no human is watching.
Two things decide what stays human
If capability is the wrong axis, two others are the right ones, and they are both properties of the decision rather than the model.
The first is the cost of being wrong — the stakes. Some errors are cheap and reversible: a mis-tagged document, a suboptimal recommendation a user can ignore. Others are catastrophic and irreversible: a wrongful denial, a safety call, a decision that harms a person or breaks a law. The higher the cost of a wrong answer, the stronger the case for a human in the path, because a human is the mechanism by which a rare but severe error gets caught before it lands. The second is how much the decision depends on context the model cannot see — judgment density. Some decisions are fully captured by the data the model has; others turn on tacit knowledge, relationships, ethical nuance, or situational context that lives outside the model's inputs entirely. The denser a decision is in that invisible context, the more a confident model output is confidently missing the point. These two axes — stakes and hidden context — are what actually determine whether a decision should stay human, and neither of them moves when the model gets better.
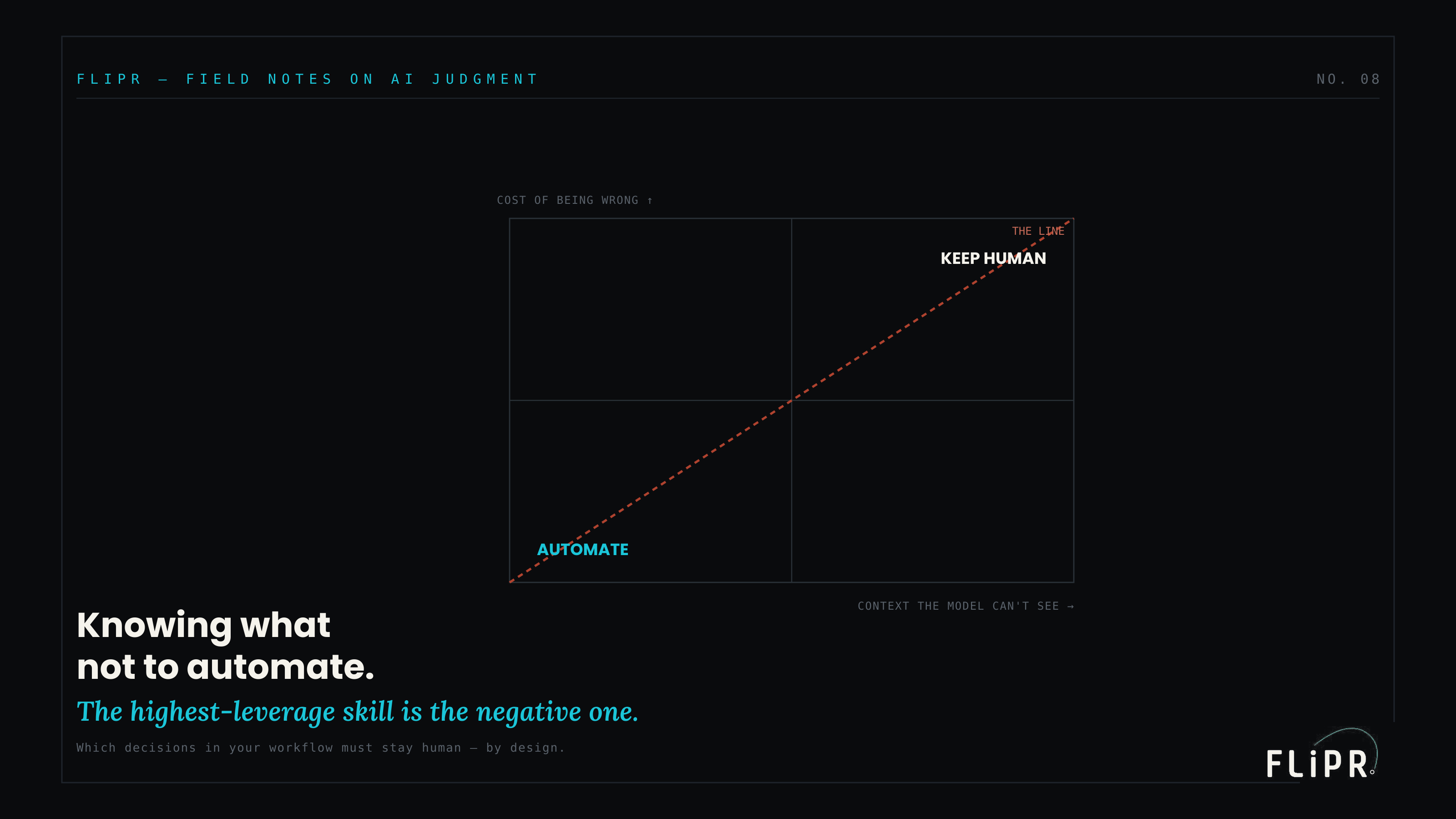
The Automation Line
Plot those two axes and a line appears that sorts every decision.
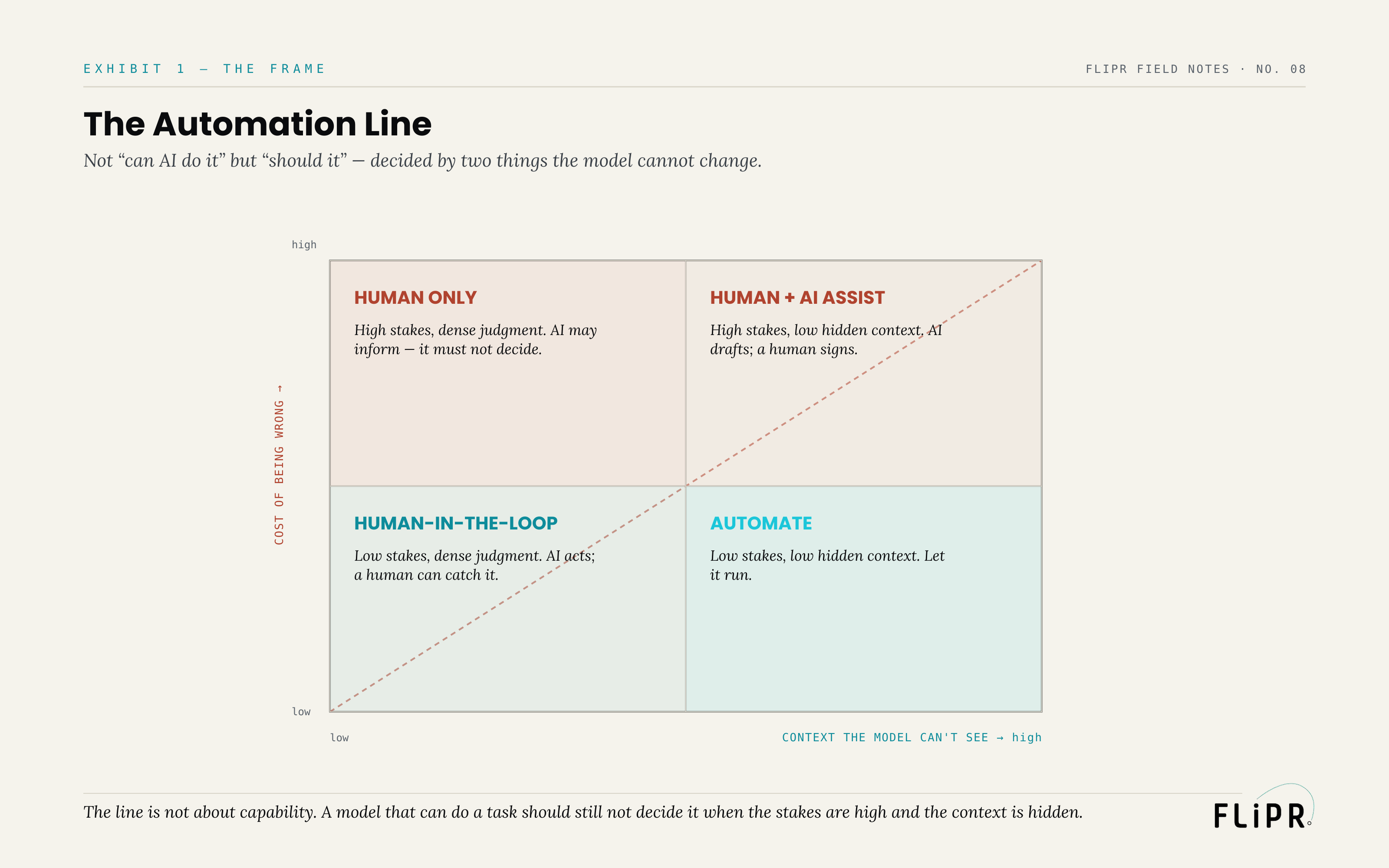 Exhibit 1. Not "can AI do it" but "should it" — decided by two things the model cannot change.
Exhibit 1. Not "can AI do it" but "should it" — decided by two things the model cannot change.
Where both the cost of being wrong and the hidden context are low, you are in the automate zone: let the system run end-to-end and sample for quality. Where stakes are low but the decision turns on context the model cannot see, you are in human-in-the-loop: the AI acts by default, but a human can review and reverse it. Where stakes are high but the decision is mostly legible to the model, you are in human plus AI assist: the AI drafts and recommends, but a human decides and signs. And where both stakes and hidden context are high, you are in the human-only zone: the AI may inform the person, but it must never make the call. The diagonal between "automate" and "human-only" is the line of the title — and the discipline is to place each decision honestly relative to it, rather than dragging everything toward "automate" because the model is capable.
The line is not drawn by what AI can do. It is drawn by consequence. A model that can technically make a high-stakes, hidden-context decision should still not be the one to make it — and knowing that, and designing for it, is the skill.
The line is not "what can AI do." It is "what should it do" — and those two lines are nowhere near each other.
Reading the quadrants
Each zone names a specific kind of decision and a specific design pattern, and the skill is matching them.
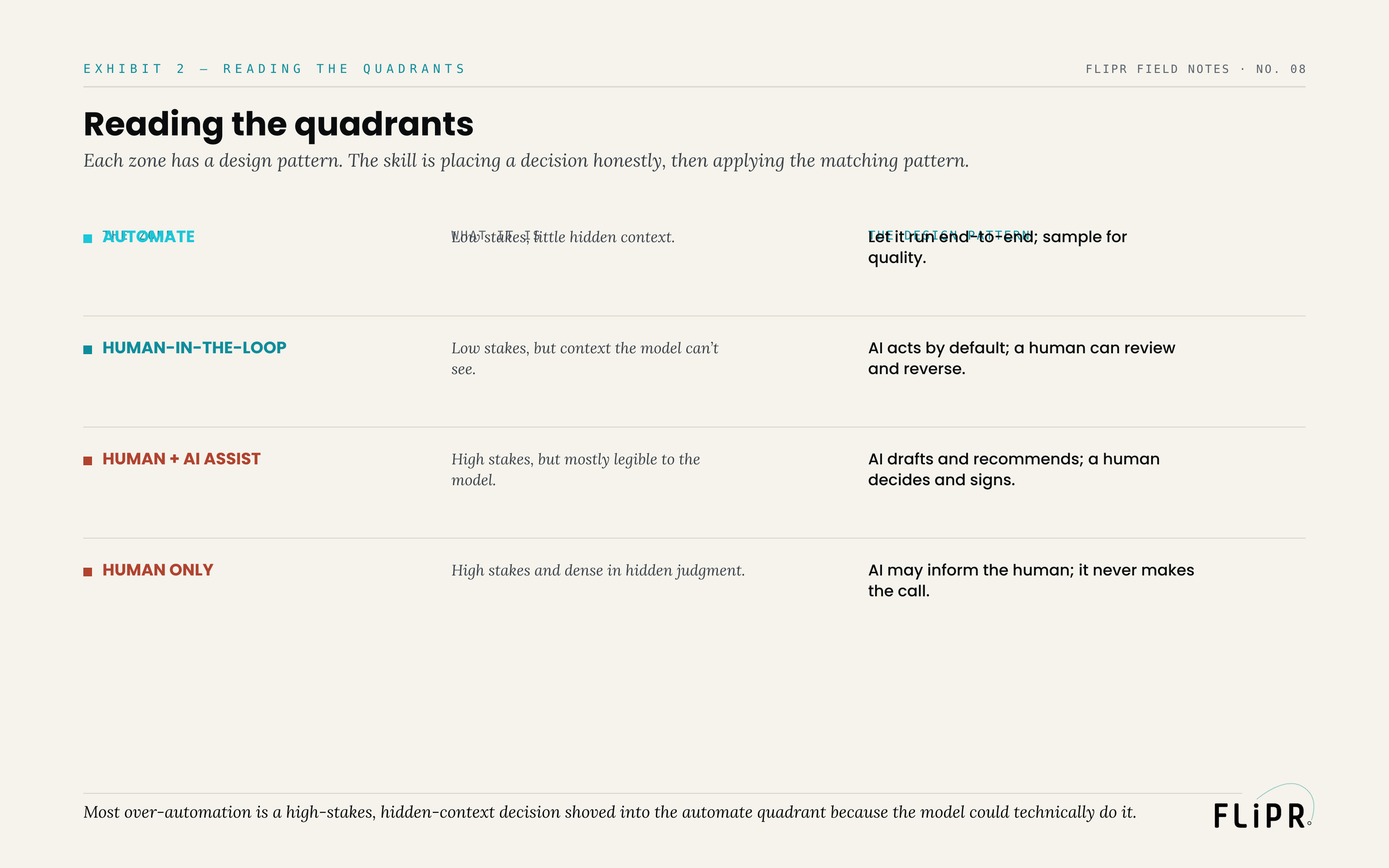 Exhibit 2. Most over-automation is a high-stakes, hidden-context decision shoved into the automate quadrant.
Exhibit 2. Most over-automation is a high-stakes, hidden-context decision shoved into the automate quadrant.
Automate is for low-stakes, low-hidden-context decisions: let it run, and sample the output for quality rather than reviewing every case. Human-in-the-loop is for low-stakes decisions that nonetheless turn on context the model lacks: let the AI act by default, but make review and reversal easy, so the rare miss gets caught cheaply. Human plus AI assist is for high-stakes decisions that are mostly legible: let the AI draft, summarize, and recommend, but keep a human making and signing the actual decision, so the speed of the model is captured without ceding the accountability. Human-only is for decisions that are both high-stakes and dense in hidden judgment: the AI may inform the human — surface data, flag patterns — but it never makes the call, because the cost of being wrong and the invisibility of the context together mean no model output should be trusted as a decision. Most over-automation is, in this frame, a single recognizable error: a decision from the high-stakes, hidden-context quadrant shoved into the automate quadrant because the model could technically produce an answer.
What this looks like on Monday
Picture two teams with the same capable model, deciding what to automate in one workflow. (This is an illustration, not an account of any specific engagement.)
 Exhibit 3. One team asked whether it could; the other whether it should. Illustrative, not a client account.
Exhibit 3. One team asked whether it could; the other whether it should. Illustrative, not a client account.
The first team automates by capability. For each decision it asks whether the model can do it, and wherever the answer is yes, it automates — including the high-stakes calls, because the demo looked capable and a human in the loop seemed like friction slowing down an obviously competent system. When one of those automated high-stakes decisions is wrong, there is no human positioned to catch it, and a single bad call erases a year of efficiency savings and then some.
The second team automates by consequence. For each decision it asks what it costs if the system is wrong and what the system cannot see, and it places the decision on the line accordingly. The low-stakes, legible work is fully automated. The high-stakes and hidden-context decisions keep a human exactly where the risk is — with the model assisting rather than deciding. Its automation footprint is smaller and less impressive on a slide, but it does not have a catastrophic failure waiting in the decisions it should never have automated.
Same model, same capability. One team asked whether it could; the other asked whether it should — and only one of them is exposed to the failure that capability alone was always going to produce.
Where this argument fails, and what it costs
This frame has limits, and they cut both ways.
The line moves, and over-caution has a cost too. As models improve and as you accumulate evidence that a given decision is safely automatable, decisions migrate toward the automate zone, and a team that draws the line once and never revisits it will be over-staffing decisions a model could now safely handle — paying in human cost and lost speed for a caution that is no longer warranted. The discipline cuts both ways: knowing what not to automate is the headline skill, but refusing to automate anything is its own failure, the mirror image of reckless automation and just as expensive over time. There is also a question of accountability the line does not resolve on its own: keeping a human "in the loop" only works if that human has the time, the information, and the authority to actually catch an error, rather than rubber-stamping a model output under volume pressure — a loop that exists on the org chart but not in practice is worse than honest automation, because it launders the model's decision as a human one.
That bounds the claim. Re-draw the line as models earn trust, guard against over-caution as carefully as over-automation, and make sure your humans-in-the-loop are real rather than ceremonial. The point is not to automate little; it is to automate by consequence rather than by capability.
The decision
Across your workflow, the move is concrete.
Take the decisions in the workflow you are automating and place each one on the two axes — cost of being wrong, and context the model cannot see — and assign it a zone: automate, human-in-the-loop, human plus AI assist, or human-only. Do this by consequence, not by capability, and be especially suspicious of any high-stakes, hidden-context decision sitting in the automate column because the model "can" do it. For everything you keep human or semi-human, make the human role real — time, information, and authority to actually catch an error — not a rubber stamp. And put a date on the map, so you re-draw the line as models earn more trust rather than freezing today's caution forever.
Models will keep getting more capable, and the temptation to automate everything they can technically do will keep growing with them. The highest-leverage skill is the one that resists that temptation precisely where it matters: knowing which decisions must stay human, because the stakes are high and the context is hidden, no matter how capable the model becomes. Draw the line by consequence, design each zone to match, and revisit it as the ground shifts. This is the same selection discipline that sits at the foundation of the companion piece on judgment — there it is named as the load-bearing layer; here is the tool for actually drawing it.
Sources
- McKinsey — The State of AI (annual survey). Risk management and human oversight among the practices associated with capturing value from AI safely. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
- Deloitte — State of Generative AI in the Enterprise (2024–2025). Trust, risk, and governance as recurring determinants of where automation is appropriate. https://www2.deloitte.com/
Bottom-line summary (one line)
The highest-leverage AI skill is knowing what not to automate, decided by two things the model can't change — the cost of being wrong and the hidden context — so place each decision on the Automation Line by consequence, not capability, and keep the high-stakes, hidden-context calls human.
Suggested LinkedIn hooks (link back to the blog)
- As models get more capable, "can AI do this?" becomes "yes" for almost everything — which is exactly why it's the wrong question. The right one is whether it should. [link]
- Automating a decision doesn't remove its risk. It relocates the risk to the one moment no human is watching. Here's how to decide what must stay human — by design. [link]
- The highest-leverage skill in enterprise AI is the negative one: knowing what not to automate. It's decided by consequence, not capability — and they're nowhere near each other. [link]