Why most enterprise AI pilots never reach production — and the four gates that change the odds
Bottom line: Enterprise AI pilots rarely die at the model. They die by attrition across four ungated checkpoints — Value, Data, Trust, and Economics — and a pilot survives to production only when a team gates each one, in order, before building. The model working is the least informative thing you can know about a pilot's odds. The gates are everything.
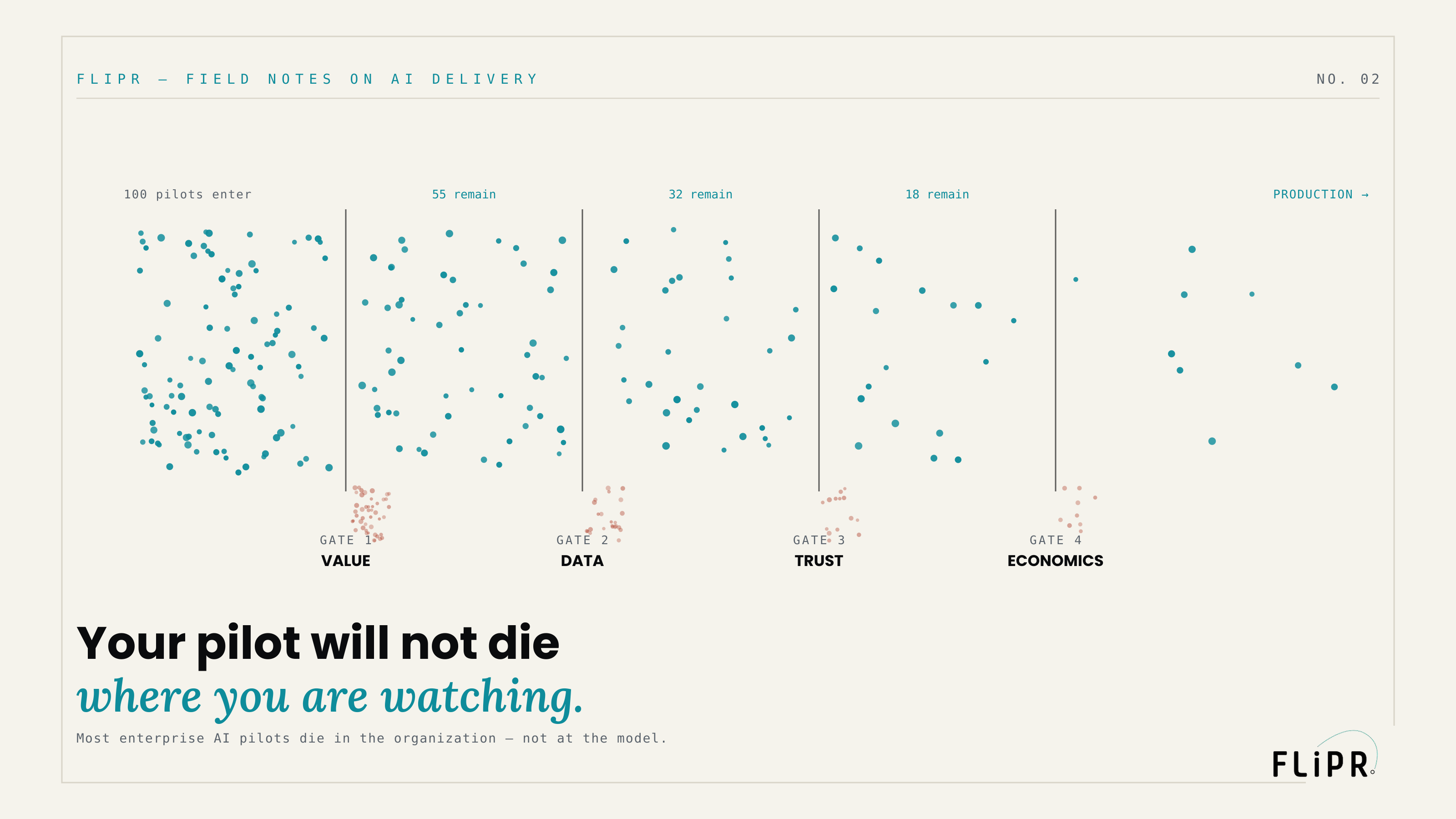
Your pilot will not die where you are watching
Most teams running an AI pilot watch the model. They track its accuracy, its latency, its benchmark scores, the quality of its outputs on a curated set. And when the model performs, they conclude the pilot is on track. This is the central mistake, and it is almost universal: the model is rarely the thing that kills the pilot. The surveys that ask enterprises why their AI initiatives stall return the same answer year after year, and it is never "the model wasn't good enough." It is data readiness, integration, workflow fit, governance, risk, talent, and adoption — the organization around the model, not the model itself (Deloitte and McKinsey state-of-AI surveys, 2024–2025).
So the dashboard that says "the model works" is measuring the wrong thing. It is bright, reassuring, and almost irrelevant to whether the pilot will reach production. The failure is coming from somewhere you are not looking — and by the time it arrives, you have usually spent the budget.
A green model dashboard is the most expensive false comfort in enterprise AI. It measures the one risk that was never going to kill you.
The failure rates disagree with each other — and that is the diagnosis
You have seen the statistics, and they do not agree. Depending on the source, somewhere between forty and ninety-five percent of enterprise AI initiatives are said to fail, stall, or never reach production. Gartner has publicly projected that the majority of generative AI projects are abandoned after proof of concept; a 2025 report from MIT's NANDA initiative found that the large majority of enterprise GenAI pilots delivered no measurable return to the profit-and-loss statement.
The instinct is to argue about which number is right. The more useful move is to notice they cannot all be measuring the same thing — and they aren't. One counts abandoned proofs of concept. Another counts pilots that deployed but produced no measurable financial return. A third counts systems that never left the lab. The range is wide because the denominators are different, and that is the diagnosis: if the failures clustered at a clean technical threshold, the model would be the cause and the numbers would converge. Instead they scatter across the messy territory after the model works. The pilots are dying in the organization, at different points, for different organizational reasons — which is exactly what you would expect if the gate is never the model.
Once you accept that, the question changes. It is no longer "is the model good enough." It is "which checkpoint is going to kill this, and have we gated it." There are four.
Four gates, in order
A pilot reaches production by passing four checkpoints, in sequence.
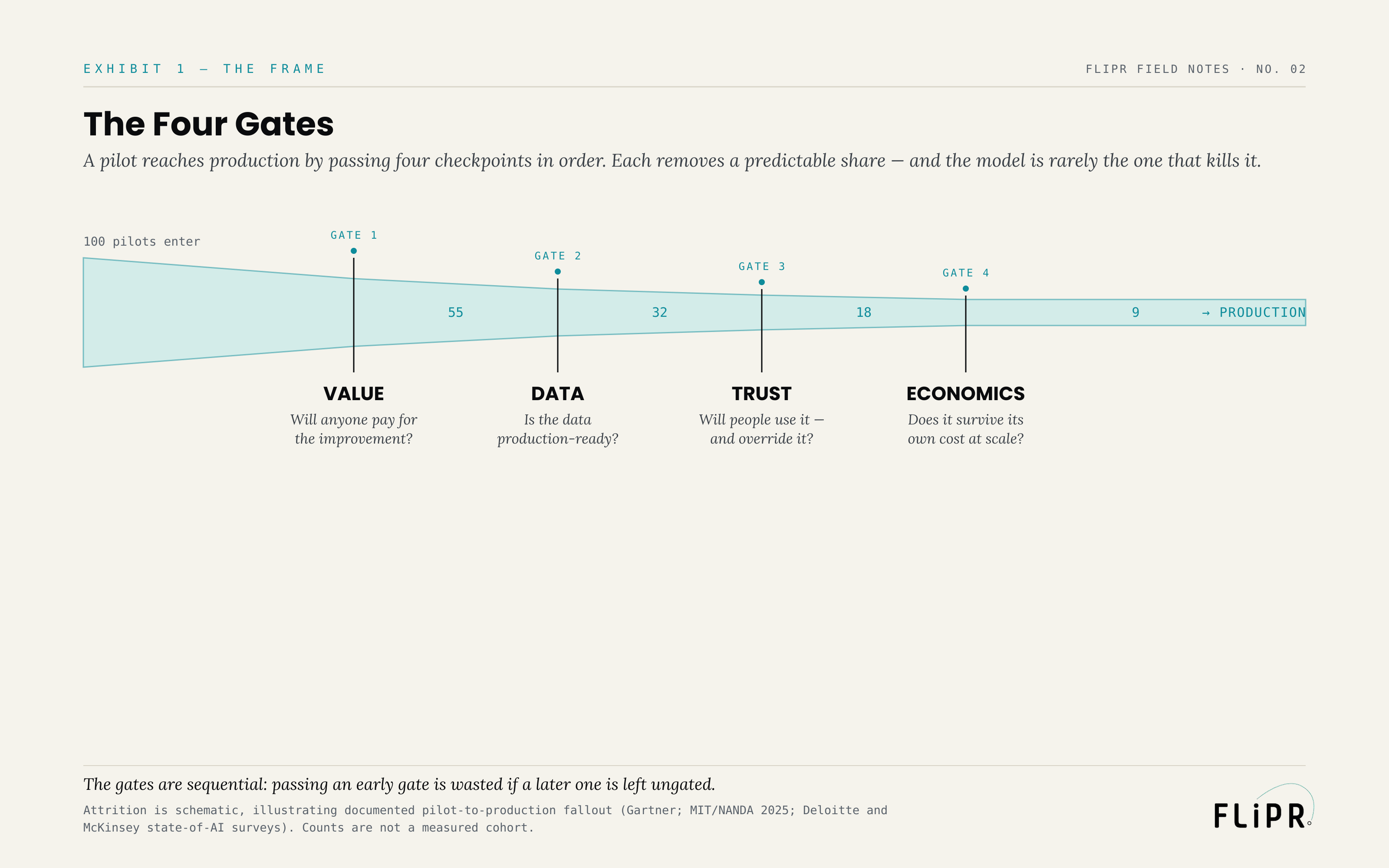 Exhibit 1. The gates are sequential — passing an early gate is wasted if a later one is left ungated. Attrition is schematic; counts are not a measured cohort.
Exhibit 1. The gates are sequential — passing an early gate is wasted if a later one is left ungated. Attrition is schematic; counts are not a measured cohort.
Gate 1 is Value: is there a decision or workflow whose improvement someone will pay for and defend? Gate 2 is Data: is the data integration-ready, governed, and available at production cadence — not just clean on a sample? Gate 3 is Trust: will the people who must use the system actually use it, and override it when it is wrong? Gate 4 is Economics: does the system survive its own total cost of ownership at production volume?
The ordering is not decoration; it is the heart of the idea. The gates are sequential, and a later ungated gate erases the work of passing an earlier one. A pilot can clear Value brilliantly — real owner, real demand — and still die at Data because the production pipeline never existed. It can clear Value and Data and die at Trust because the experts who were supposed to use it never did. It can clear the first three and die at Economics because the unit cost that was fine at pilot volume is ruinous at scale. Passing a gate is necessary, never sufficient. The pilot survives only if every gate is gated, and most teams gate none of them — they gate the model, which is not on the list.
This is why "we proved it works" is such a dangerous sentence. It almost always means the team passed an informal version of one gate and left the other three to chance.
What each gate actually checks
Each gate has a tell. Learn the failure signature and you can read a pilot's odds before it ships.
 Exhibit 2. Each gate has a tell. If you cannot state the pass test, the gate is not gated — it is just a hope.
Exhibit 2. Each gate has a tell. If you cannot state the pass test, the gate is not gated — it is just a hope.
Value. The failure signature is the impressive demo with no owner — a slick capability nobody in the business is accountable for and nobody will fund past the applause. The pass test is concrete: a named owner and a number they will commit to. Not "this could help marketing," but "this person owns this metric and will defend the budget when it is questioned." If no one will put their name and a number on it, the pilot has already failed Gate 1; everything after is motion.
Data. The failure signature is the system that worked on the sample and broke on the pipe — flawless on the hand-picked test set, then starved or poisoned by the real data flow it meets in production. The pass test is that the system runs end-to-end on real, live, governed data, at the cadence production will demand, before you scale it. Data readiness is the single most common place a technically-working pilot quietly dies, because the sample always looks better than the pipe (Deloitte and McKinsey surveys, 2024–2025).
Trust. The failure signature is the deployed system whose logins stay flat — shipped, announced, and unused. The people best positioned to judge an AI tool are usually your most experienced people, and when they do not adopt it they are often telling you something true about its failure modes. The pass test is that experts use the system unprompted and can override it when it is wrong. Adoption you have to mandate is not adoption; it is compliance with a memo, and it ends the moment the memo is forgotten.
Economics. The failure signature is the green pilot with red unit economics — a system that hits every milestone and costs more per query at production volume than the value it creates. The pass test is a total-cost-of-ownership model built at production scale, with a kill condition agreed in advance. The most dangerous project is not the one that fails loudly; it is the one that succeeds at the wrong thing and runs for years because it looks green and nobody kills a green project.
If you cannot state the pass test for a gate, the gate is not gated. It is just a hope.
One observation from our own delivery work is worth naming, because it predicts trouble earlier than any technical signal: the order in which a team discovers its gates is itself a tell. Healthy pilots tend to surface the Data and Economics questions early, while the work is still cheap to stop — someone asks "can the pipeline even feed this at production cadence, and what does that cost" in the first weeks. Troubled pilots discover those same questions late, after the demo has won applause and the budget is committed, when the honest answer is most expensive to act on. The gates do not move. What moves is when you choose to look at them — and looking late is the most reliable predictor of a pilot that dies after the spend.
Run the gates on Monday
Set two pilots side by side inside the same company — same model, same budget, same quarter. (This is an illustration, not an account of any specific engagement.)
 Exhibit 3. Same pilot, two regimes. The cheapest failure is the one you cause early, on purpose. Illustrative, not a client account.
Exhibit 3. Same pilot, two regimes. The cheapest failure is the one you cause early, on purpose. Illustrative, not a client account.
The first pilot is ungated. The team confirms the model works on a demo and proceeds, applying no real check at any gate. It runs the whole way. Then it dies — late, at the Economics or Data gate it never tested — after the budget is spent, the team is committed, and the political cost of stopping is highest. The failure is expensive precisely because it is late: every dollar and every month of momentum is sunk before the gate that was always going to kill it finally does.
The second pilot is gated. The team applies a real pass test at each gate. It clears Value — there is an owner and a number. Then at the Data gate it discovers the production pipeline cannot deliver the data at the cadence required, and the cost to build it dwarfs the value. So the team stops. It kills the pilot at Gate 2, early, on purpose, having spent a fraction of the first team's budget. That looks like a failure on a status report. It is the most valuable thing the team did all quarter.
Same model. The only difference is whether the gates were gated — and the gated team's "failure" is cheaper than the ungated team's "success" was ever going to be.
Where gating fails, and what it costs
Every frame has edges worth naming, and this one is no exception.
Gating can be over-applied, and when it is, it strangles the exploration that AI genuinely rewards. Some bets are worth making precisely because their value is uncertain — a research probe, a strategic option, a capability you are building ahead of demand. Forcing those through a Value gate that demands a committed number on day one will kill the very experiments that justify an AI program's existence. The gates are for pilots aimed at production, not for every exploratory spike. A mature organization knows which is which and does not gate the things that are supposed to be ungated.
There is also a real cost to gating, and it is not small. Gates add friction. They are slower to start than "let's just build it and see." They look bureaucratic to a leadership team that rewards visible momentum, and they force the organization to say no to projects that look green and feel exciting. Choosing to gate is choosing to kill things early and on purpose, in a culture that usually punishes killing things at all. If your incentives reward launches over outcomes, the gates will lose every internal argument until you change the incentives — which is the harder, prior work.
That bounds the claim without breaking it. Do not gate exploration. Do gate anything headed for production. And fix the incentive that makes an early, cheap kill look worse than a late, expensive failure.
The decision
That points to a concrete move before your next pilot.
Assign each of the four gates an owner and a written pass test — the specific condition that must be true to proceed. Do this before you build, not after, because a gate defined after the spend is not a gate; it is a rationalization. Pre-commit a kill condition at Gate 1, so that stopping is a planned outcome rather than an admission of failure. And move your attention off the model. Stop treating "the model works" as evidence the pilot is healthy, and start treating the gates as the only scoreboard that predicts production.
Most AI pilots die in the organization, quietly, after the model has already proven it works — which is why watching the model tells you almost nothing. Watch the gates instead. Gate them in order, gate them before you build, and accept that a pilot killed early at Gate 1 is the cheapest win you will book all year. The teams that reach production are not the ones with the best models. They are the ones that knew, before they started, exactly how their pilot was most likely to die — and gated against it.
These four gates are the operational floor beneath a larger strategic shift: as the cost of model capability collapses, the advantage moves from having the capability to the judgment of how to deploy it. The gates are where that judgment becomes a checklist a delivery team can actually run. The companion piece on capability and judgment makes the strategic case; this one is how it survives contact with a real build.
Sources
- Gartner. Public projection that the majority of generative AI projects are abandoned after proof of concept. https://www.gartner.com/en/newsroom
- MIT NANDA — The State of AI in Business 2025. Finding that the large majority of enterprise GenAI pilots showed no measurable P&L return.
- Deloitte — State of Generative AI in the Enterprise (2024–2025). Leading barriers to scaling are organizational: data quality and governance, integration, risk, talent. https://www2.deloitte.com/
- McKinsey — The State of AI (annual survey). Organizational and data-readiness barriers as the primary obstacles to capturing value from AI. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
- Stanford HAI — Artificial Intelligence Index Report 2025. Inference price trends relevant to the Economics gate — per-query cost falling, but routinely under-modeled at production scale. https://aiindex.stanford.edu/report/
Bottom-line summary (one line)
Enterprise AI pilots die in the organization, not at the model — so gate the next one against the four checkpoints that actually kill pilots (Value, Data, Trust, Economics), in order, before you build.
Suggested LinkedIn hooks (link back to the blog)
- Your AI pilot's model dashboard is green. That tells you almost nothing about whether it will reach production — because the model is rarely what kills a pilot. Here is what does. [link]
- Forty percent of AI pilots fail. Or ninety-five. The numbers disagree because they measure different things — and that disagreement is the most useful diagnosis in enterprise AI. [link]
- The cheapest win your AI team can book this year is a pilot you kill early, on purpose, at the right gate. Four gates, in order — and why the order is the whole point. [link]