Evals are the product: the test suite that decides whether your AI survives
Bottom line: In a traditional system you can read the code and reason about whether a change is safe. In an AI system you cannot — its behavior is non-deterministic and emergent, so the only thing that tells you whether a change helped or hurt is your evaluation suite. That makes evals not a quality-assurance afterthought but the core product surface: without them, every improvement is a guess, and every release is a roll of the dice. The discipline is a pyramid of evals, built from the bottom up, that you cannot skip and still trust what sits above.

You cannot eyeball a non-deterministic system
Traditional software has a property engineers rely on without noticing: it is inspectable. You can read the code, trace the logic, and reason about whether a change is safe before you ship it. A function that worked yesterday works today. Quality assurance is a confirmation step on top of a system you already understand.
AI breaks that property. A system built on a probabilistic model is non-deterministic — the same input can produce different outputs — and its behavior is emergent rather than written down, so you cannot read it to know what it will do. Change a prompt, swap a model version, adjust a retrieval parameter, and you have altered the behavior of the whole system in ways no one can predict by inspection. The instinct carried over from traditional software — try it on a few examples, and if it looks better, ship it — fails silently here, because a handful of examples cannot characterize a system whose behavior varies across thousands of inputs. You are not confirming the behavior of a system you understand; you are sampling the behavior of one you do not. The only way to know whether a change helped is to measure it against many cases, systematically, every time. That measurement is what an eval is.
You can read traditional software to know what it does. You can only measure an AI system — which means the measurement is not optional.
Evals are not QA. They are the product's nervous system.
This is why treating evals as quality assurance — a gate someone runs near the end, owned by a separate team, resented as a tax on shipping — gets the role exactly wrong. In an AI system, evals are the sensory apparatus through which you perceive the product at all. They are how you know whether the thing works, whether a change is an improvement or a regression, whether today's version is better or worse than last week's. Strip them away and you are not shipping faster; you are flying blind and calling it speed.
The reframe has a practical consequence. If evals are the nervous system, they are built first and maintained continuously, not bolted on before a launch. They are owned by the people building the product, not quarantined in a QA function. And they are the asset that compounds: a mature eval suite is the institutional memory of every failure mode you have ever found, encoded so you never ship into it again. Teams that internalize this move faster over time, because a good suite makes change safe to make. Teams that treat evals as overhead slow down, because every change carries the risk of silent breakage they have no way to detect. "Without evals, you're guessing with extra steps" is not a slogan; it is a literal description of shipping AI without measurement.
The Evaluation Pyramid
Evals are not one thing. They are four layers, built from the bottom up.
 Exhibit 1. Four layers of test, built bottom-up. You cannot skip a layer and trust what sits above it.
Exhibit 1. Four layers of test, built bottom-up. You cannot skip a layer and trust what sits above it.
At the base are unit evals: does each component — the retrieval step, the parser, the tool call — do its individual job correctly? Above them, capability evals: does the whole system, assembled, actually perform the task on representative inputs? Above those, behavior and safety evals: does the system fail gracefully — refuse when it should, avoid hallucinating with false confidence, degrade safely at the edges? And at the apex, outcome evals: does the system move the business metric it exists to move? The pyramid shape is deliberate. The base is broad and foundational — many components, many cases — and the apex is narrow and high-stakes, the single number leadership actually cares about.
The order is not a suggestion; it is a dependency chain. You build from the base up because each layer depends on the ones beneath it. An outcome number you cannot trace down to capability and unit evals is a number you cannot act on — when it moves, you have no idea why, and no way to reproduce the win or diagnose the loss. Skipping the base to chase the apex is the most common eval mistake, and it produces a dashboard that looks like measurement but supports no decisions.
An outcome metric with no evals beneath it is not a measurement. It is a number you cannot explain, attached to a system you cannot debug.
What each layer catches — and what skipping it costs
Each layer of the pyramid catches a specific class of failure, and skipping a layer does not remove that failure — it just relocates the discovery of it to production.
 Exhibit 2. The cost of a missing layer is always paid in production.
Exhibit 2. The cost of a missing layer is always paid in production.
Unit evals catch broken components; skip them and failures hide inside a system that "mostly works," surfacing unpredictably and impossible to localize. Capability evals catch task regressions; skip them and you ship a change that helps the one case you checked and quietly breaks ten you did not. Behavior and safety evals catch the dangerous edges; skip them and the system that demoed beautifully harms a real user in a case no one tested — the failure mode that turns an AI launch into an incident. Outcome evals catch the most expensive failure of all: the system that hits every technical mark and moves no business metric, the green dashboard delivering no value that nobody thinks to question because it looks like success. The cost of a missing layer is always paid, and it is always paid later and more expensively, in production, in front of the people you least wanted to discover it.
What this looks like on Monday
Picture two teams shipping the same AI feature on the same model. (This is an illustration, not an account of any specific engagement.)
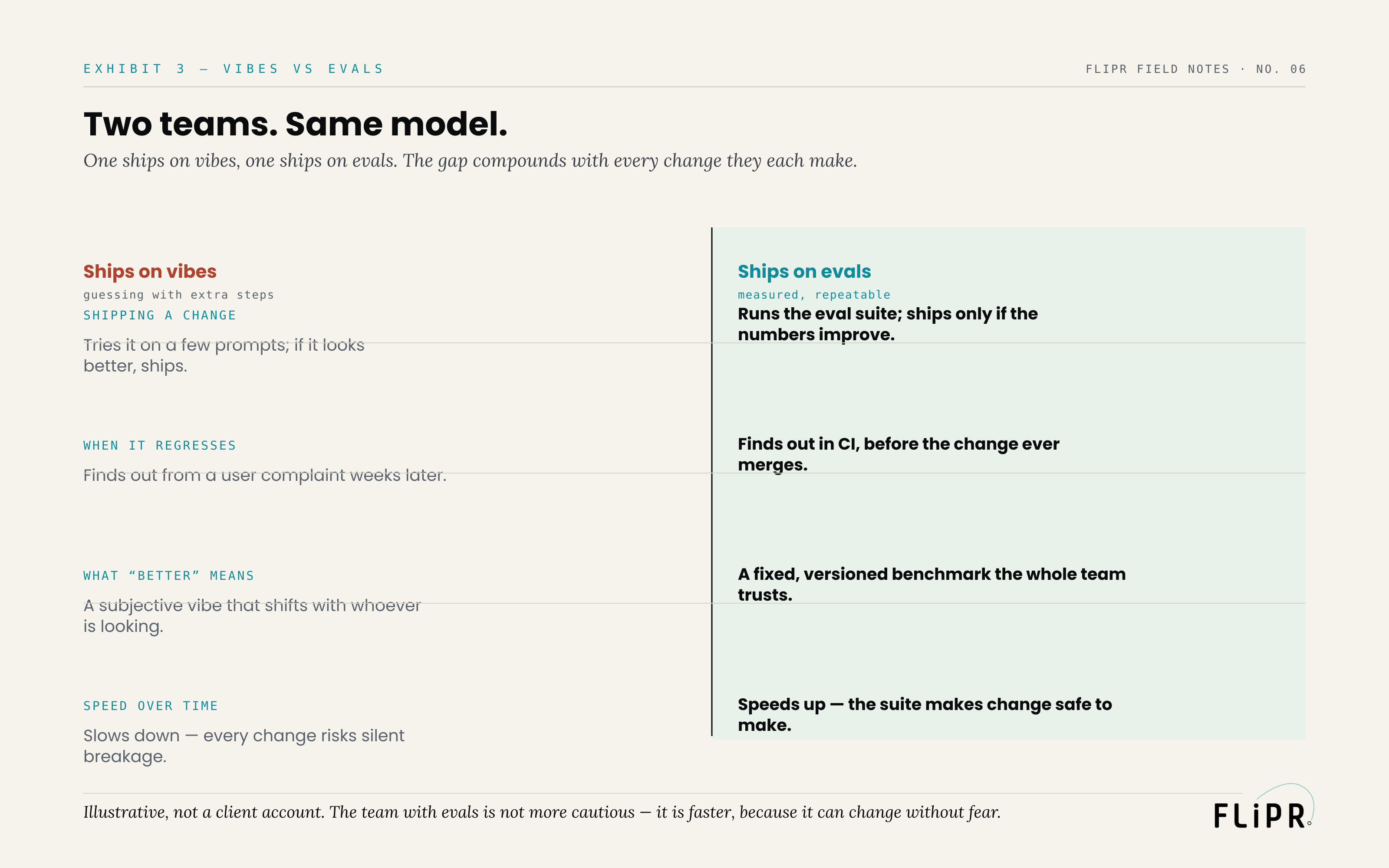 Exhibit 3. The team with evals is not more cautious — it is faster. Illustrative, not a client account.
Exhibit 3. The team with evals is not more cautious — it is faster. Illustrative, not a client account.
The first team ships on vibes. To evaluate a change, it tries the new version on a few prompts; if the outputs look better to whoever is looking, it ships. When the change quietly regresses something, the team finds out weeks later from a user complaint. "Better" means whatever the most recent reviewer felt, a standard that drifts with mood and personnel. Over time the team slows to a crawl, because every change risks breaking something invisible and no one can move with confidence.
The second team ships on evals. Every change runs against the suite; it ships only if the numbers improve, and a regression is caught in continuous integration before the change ever merges. "Better" means a measurable gain on a fixed, versioned benchmark the whole team trusts. Over time this team speeds up, because the suite makes change safe — they can refactor, swap models, and rewrite prompts without fear, because the nervous system will tell them immediately if they broke something.
Same model, same feature. The team with evals is not more cautious. It is faster — because measurement is what lets you move without flinching.
Where this argument fails, and what it costs
This argument has real limits.
Evals can be gamed, including by accident. A suite optimized too hard becomes a target rather than a measure — the team learns to pass its own benchmark while the real-world behavior drifts, the classic failure of any metric that becomes an objective. Guarding against that means refreshing the suite with new failure cases continuously and resisting the temptation to treat a high eval score as the goal rather than a proxy for it. There is also a real cost to eval infrastructure: building and maintaining a serious suite is engineering work, and for a genuinely throwaway prototype it can be overkill — the discipline scales with how much you intend to depend on the system. And some things genuinely resist evaluation: the hardest, highest-judgment outputs, where "good" is contested even among experts, cannot be reduced to a metric without losing what matters, and forcing them into one produces false confidence. For those, evals inform a human judgment rather than replacing it.
That bounds the claim. Refresh the suite so it stays a measure and not a target, scale the investment to your dependence on the system, and keep a human in the loop where "good" cannot honestly be reduced to a number. The point is not that everything is measurable; it is that what you can measure, in a system you cannot read, you must.
The decision
Before you scale your next AI system, the move is concrete.
Build the pyramid from the base before you scale, not after. Stand up unit evals on your components, capability evals on the assembled task, behavior and safety evals on the edges, and an outcome eval tied to the metric that justifies the system — in that order, because each depends on the one below. Wire the suite into continuous integration so no change ships without passing it, and treat the suite as a first-class product surface owned by the people building the system, not a QA function bolted on at the end. Then refresh it continuously with every new failure you find, so it stays a living measure rather than a stale target.
The model will keep changing under you, your prompts will keep evolving, and every one of those changes will alter a system you cannot read. Evals are the only thing standing between that reality and shipping blind. Build them first, build them in order, and treat them as the product — because in AI, they are. The gates in the companion piece on why pilots never reach production are, in the end, run on evals; and a mature eval set is itself a piece of the proprietary data exhaust that the data-moat piece argues is your most durable asset.
Sources
- Deloitte — State of Generative AI in the Enterprise (2024–2025). Quality, reliability, and risk management among the leading obstacles to scaling AI — the gap evals are built to close. https://www2.deloitte.com/
- McKinsey — The State of AI (annual survey). Inconsistent performance and the difficulty of measuring AI value among the barriers to capturing returns. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Bottom-line summary (one line)
In a system you cannot read, the eval suite is the only thing that tells you whether a change helped — so build the Evaluation Pyramid (unit, capability, behavior, outcome) from the base up, wire it into CI, and treat it as the product rather than QA.
Suggested LinkedIn hooks (link back to the blog)
- You can read traditional software to know what it does. You can only measure an AI system. That one difference makes your eval suite the product — not a QA step. [link]
- "Without evals, you're guessing with extra steps." That's not a slogan — it's a literal description of shipping a non-deterministic system you have no way to measure. [link]
- The team with the eval suite isn't more cautious. It's faster — because measurement is the only thing that lets you change an AI system without flinching. Here's the pyramid. [link]