The agent reliability problem: why your multi-step AI keeps breaking
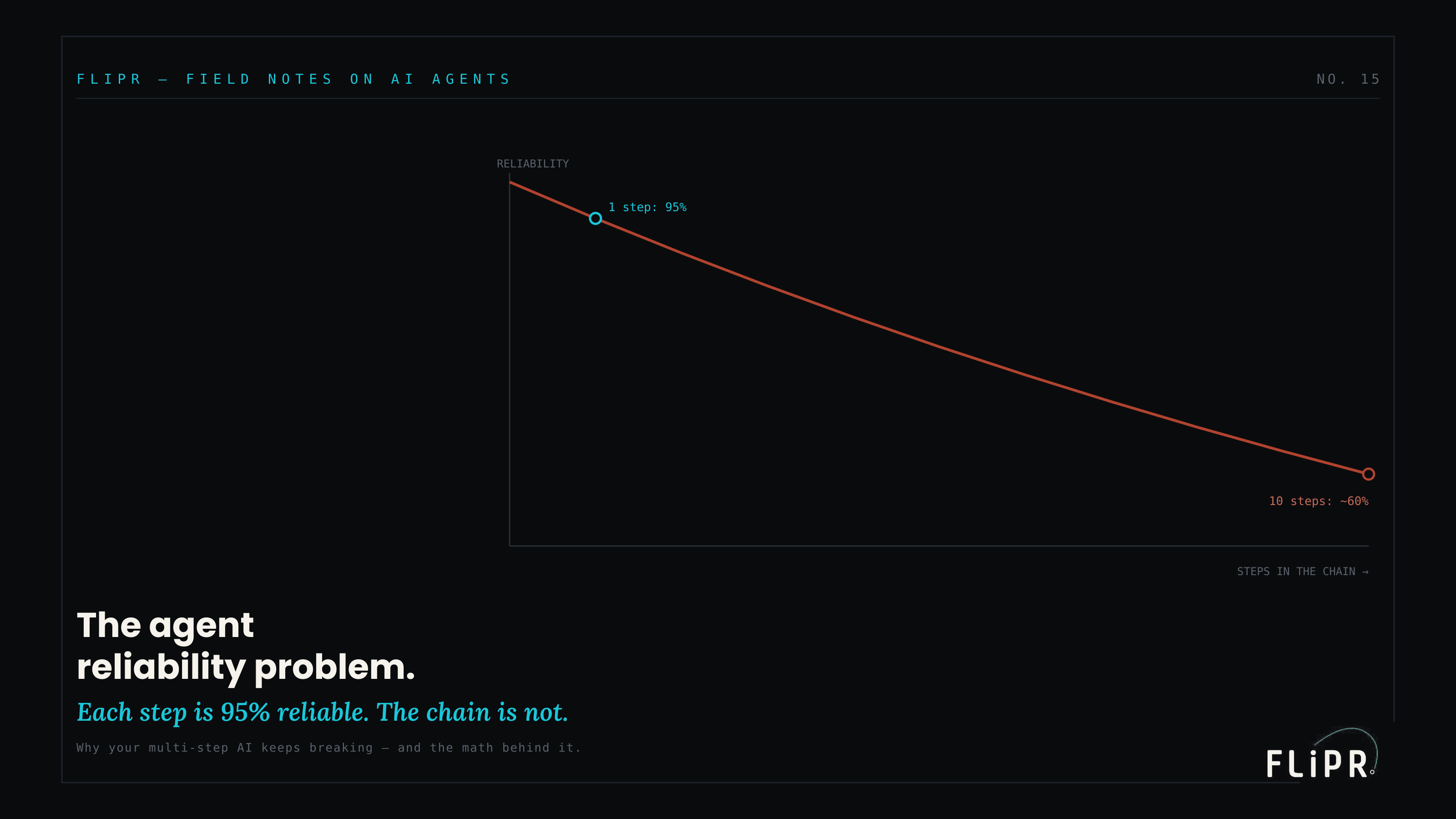
Bottom line: A single AI call that is 95% reliable feels excellent. Chain ten of them together in an agent and you are at roughly 60%, because reliability compounds down multiplicatively across steps, not up. This is the hidden arithmetic that makes impressive agent demos collapse in production: each step is individually fine, but the chain is fragile by construction. The fix is not a better model — it is system design: fewer steps, checkpoints that catch errors before they propagate, independent steps that fail locally, and recovery that does not restart the chain. Agent reliability is an architecture property, and the naive approach pays a compounding tax.
Your agent demo lied to you
The agent demo is one of the most seductive artifacts in AI. A chain of steps — retrieve, reason, call a tool, summarize, act — executes flawlessly, and the result feels like magic: the system did a whole multi-step task on its own. The instinct is to conclude that the approach works and to ship it. Then it reaches production, and the magic becomes maddening: the same agent that ran perfectly in the demo now fails unpredictably, succeeding one time and breaking the next, in ways that are hard to reproduce and harder to fix. The demo was not dishonest, exactly. It just showed you the agent on one happy path, on one good run, and a single good run tells you almost nothing about how a chain behaves across many runs.
The reason is mathematical, not anecdotal, and it is the single most important thing to understand about multi-step AI. Each step in an agent has some probability of being correct. When you chain steps, those probabilities multiply, because the whole chain only succeeds if every step succeeds. A demo is one sample from that distribution — and the most likely single sample to be shown is a successful one, because that is the one worth demoing. Production is thousands of samples, and across thousands of samples the multiplicative math asserts itself ruthlessly. The demo showed you the best case; production gives you the average case; and for a chain, those two are very far apart.
A demo is one good run of the chain. Production is thousands of runs. For a multi-step agent, those are not remotely the same number.
Reliability compounds down, not up
Here is the arithmetic, because it is the whole argument. Suppose each step in your agent is 95% reliable — an excellent figure for a single AI call, the kind of number that would make you confident in one step. Chain two such steps and the chain is 0.95 × 0.95 ≈ 90% reliable. Chain five and you are at roughly 77%. Chain ten and you are at about 60% — a coin flip with a slight edge, built entirely out of steps that were each individually excellent. Nothing went wrong with any single step; the degradation is purely the consequence of multiplying probabilities that are each below one.
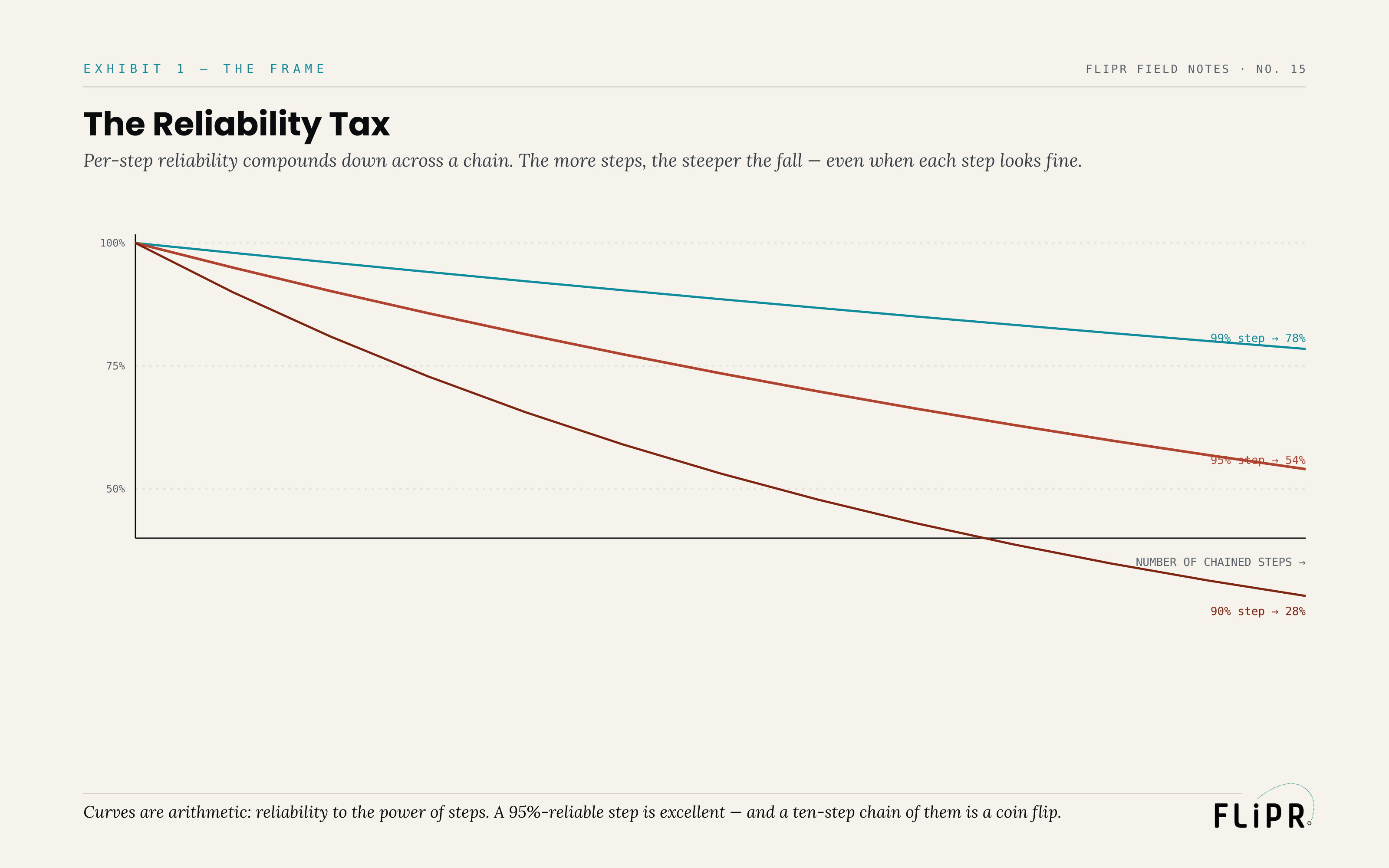 Exhibit 1. Per-step reliability compounds down across a chain. The more steps, the steeper the fall — even when each step looks fine.
Exhibit 1. Per-step reliability compounds down across a chain. The more steps, the steeper the fall — even when each step looks fine.
The shape of this is worth internalizing, because it is steep and counterintuitive. We intuitively expect that a chain of reliable things is reliable, the way a chain of strong links is strong — but reliability does not work like strength. It works like a tax applied at every step, compounding downward. Raising per-step reliability helps, but not as much as you would hope: even at 99% per step, a twelve-step chain is only about 89% reliable, and most real agent steps are nowhere near 99%. And lowering it is catastrophic: at 90% per step, that same twelve-step chain is down around 28%. The lesson is that the number of steps matters at least as much as the reliability of each step, and often more — which means the most powerful reliability lever is frequently not making steps better but having fewer of them.
Reliability is not like strength. A chain of strong links is strong; a chain of reliable steps is a tax compounding downward at every link.
The Reliability Tax
Call this the reliability tax: the multiplicative penalty a multi-step agent pays simply for having steps. It is not a bug to be fixed but a property to be designed around, and the good news is that it is an architecture problem, which means architecture can address it.
 Exhibit 2. Reliability is a system-design property, not a model property. The first move — fewer steps — beats all the others.
Exhibit 2. Reliability is a system-design property, not a model property. The first move — fewer steps — beats all the others.
There are four moves, in rough order of leverage. Fewer steps is the biggest win: every step you remove from the chain stops compounding entirely, so collapsing a chain — doing more per call, eliminating unnecessary hops — attacks the tax at its root. Checkpoints verify a result before passing it downstream, catching an error early instead of letting it propagate and corrupt every step after it. Independent steps are designed not to depend on each other, so a failure stays local rather than cascading through the chain. And mid-chain recovery lets the agent retry or fall back without restarting the whole sequence, turning a fatal failure into a recoverable one. None of these is about the model; all of them are about how the system around the model is structured. The first move dominates the rest, because the cheapest step to make reliable is the one you removed from the chain altogether — a step that does not exist cannot fail, and cannot tax the steps after it.
This is why agent reliability is a system-design discipline, not a model-selection one. You do not buy your way out of the reliability tax with a better model; you architect your way out of it by respecting the arithmetic — minimizing steps, verifying between them, isolating them, and recovering within them.
What this looks like on Monday
Set two agents side by side, both built on steps with the same 95% per-step reliability. (This is an illustration, not an account of any specific engagement.)
 Exhibit 3. Same per-step reliability; one chains naively, one architects for the tax. Illustrative, not a client account.
Exhibit 3. Same per-step reliability; one chains naively, one architects for the tax. Illustrative, not a client account.
The first chains naively. Its design instinct is to add more steps, because each one looks reliable enough on its own and more steps mean more capability. Its demo runs flawlessly on the path it was shown. In production it fails unpredictably as small errors compound across the chain, and when a single step fails, the whole chain collapses and restarts from the beginning. The team is baffled, because every individual step works — which is exactly the trap, since the failure was never in any step but in the multiplication of them.
The second architects for reliability. Its design instinct is to minimize steps and treat each one as a reliability cost to be justified. It is tested across many runs, where the tax shows up and can be managed, rather than on a single happy path. In production it degrades gracefully, with checkpoints catching errors early, and when a step fails it recovers mid-chain and continues rather than collapsing. Same per-step reliability as the first agent, very different production behavior — because the second agent was designed in respect of the arithmetic and the first was designed in ignorance of it.
Same 95% steps in both. One chained them naively and shipped a coin flip; the other architected for the tax and shipped something dependable.
Where this argument runs out
There are limits to this, and they matter.
Some tasks genuinely require many steps, and "use fewer steps" is not always available — a complex workflow may irreducibly involve a dozen distinct operations, and the answer there is not to pretend otherwise but to invest heavily in the other three moves: checkpoints, independence, and recovery, which become more important the longer the chain has to be. There is also a cost to over-architecting reliability: every checkpoint adds latency and expense, and a chain so wrapped in verification that it is slow and costly can be its own failure, so the rigor should scale with the stakes of the task rather than being applied uniformly. The independence move has limits too — many agent steps are genuinely dependent by nature, where each step needs the output of the last, and you cannot design that dependency away, only manage it. And mid-chain recovery is not free or always possible; some failures are not recoverable, and for those the honest move is to fail cleanly and escalate rather than to paper over an unrecoverable error. The arithmetic is real, but the response to it is a set of trade-offs, not a free lunch.
That bounds the claim. Invest most in checkpoints and recovery when steps are genuinely irreducible, scale the rigor to the stakes, manage dependency you cannot remove, and fail cleanly when recovery is not possible. The point is not that agents cannot work; it is that they work only when designed in respect of the compounding tax, not in denial of it.
The decision
So the move, before you ship your next multi-step agent, is concrete.
Count the steps in your chain and treat that count as the primary reliability risk, not the model — then attack it: collapse steps wherever you can, because the cheapest reliable step is the one you removed. For the steps that remain, add checkpoints that verify results before they propagate, design steps to be as independent as the task allows so failures stay local, and build mid-chain recovery so a single failure does not collapse the whole sequence. Test across many runs rather than trusting a single good demo, because the tax only shows up in the aggregate. And scale all of this to the stakes — a low-stakes agent can tolerate a fragility that a high-stakes one cannot.
The demo will always look better than production, because the demo is one good run and production is the average of thousands, and for a multi-step chain those are far apart. Respect the arithmetic: reliability compounds down, the number of steps is the dominant lever, and architecture — not a better model — is how you pay down the tax. Build agents that are designed in respect of the compounding math, and you ship the dependable system instead of the impressive demo that collapses. This is the agentic-systems specialization of the general failure design in the companion piece on when the model is wrong, where checkpoints are the detection rung and recovery is the recovery rung; the verification those checkpoints run is the eval discipline from the piece on evals.
Sources
- Stanford HAI — Artificial Intelligence Index Report 2025. Per-task model performance benchmarks, useful as the per-step reliability inputs the compounding argument builds on. https://aiindex.stanford.edu/report/
- Deloitte — State of Generative AI in the Enterprise (2024–2025). Reliability and production-readiness among the leading obstacles to deploying agentic and multi-step AI. https://www2.deloitte.com/
Bottom-line summary (one line)
Reliability compounds down across chained steps — ten 95%-reliable steps make a ~60%-reliable agent — so treat step count as the primary risk and architect for the Reliability Tax with fewer steps, checkpoints, independence, and mid-chain recovery rather than reaching for a better model.
Suggested LinkedIn hooks (link back to the blog)
- Your agent demo lied to you — not on purpose. A demo is one good run of the chain; production is thousands. For a multi-step agent, those are nowhere near the same number. [link]
- Each step is 95% reliable, so the agent is reliable, right? Chain ten and you're at ~60%. Reliability compounds down, not up — and step count is the dominant lever. [link]
- The cheapest step to make reliable is the one you removed from the chain. Agent reliability is an architecture problem, not a model problem. Here's the compounding tax. [link]